Poniższy szablon należy odpowiednio uzupełnić.
- Układ należy zachować (z dopuszczeniem minimalnych modyfikacji).
- Opis nie powinien przekraczać 10 stron przeciętnego ekranu laptopa.
- W razie potrzeby należy założyć podstrony (na końcu z rozdziałem "Co dalej?" i odnośnikiem do kolejnego rozdziału dokumentacji).
- Język opisu - polski. W sytuacji, gdy zasadnicza dokumentacja usługi ma być po angielsku, w tym rozdziale powinny znaleźć się podstawowe informacje pozwalające zorientować się w zaletach usługi i zgrubnie w wymaganych krokach do jej uruchomienia.
- Uprawnienia do odczytu strony (Tools/Restrictions) powinny być ustawione na "Confluence-users" w trakcie pisania dokumentacji, inaczej będzie widoczna od razu dla osób niezalogowanych.
- Pytania dotyczące systemu dokumentacji: Hubert Siejkowski,
- Pytania dotyczące Podręcznika Użytkownika: Unknown User (plgfilocha).
Wstawianie odnośników do innych stron podręcznika
Przy wstawianiu linków do stron wewnętrznych Podręcznika użytkownika (np. certyfikat="Aplikowanie, rejestracja i użycie certyfikatu"' założenie konta="Zakładanie konta w portalu"; Pomoc="Gdzie szukać pomocy") należy w trybie edycji strony:
- wpisać tekst, pod który będzie podpięty link
- zaznaczyć tekst
- wstawić link (Ctrl+K lub ikona Link na pasku narzędzi)
- wybrać opcję Search z lewej strony okna Insert Link
- w pasku po prawej wpisać tytuł strony (lub zacząć wpisywać tytuł i wybrać właściwą stronę z pojawiających się podpowiedzi)
- zatwierdzić wybraną stronę opcją Insert w prawym dolnym rogu
Efekt powyższego opisu można zobaczyć klikając lewym klawiszem myszki (w trybie edycji strony) na dowolny link w tym oknie informacji. Pojawi się pole, w którym do wyboru będzie opcja Edit, którą klikamy. Pojawi się okno Edit link, z aktywnym polem Search i nazwą strony wewnętrznej podręcznika.
Proszę nie wstawiać odnośników do innych części podręcznika jako linki zewnętrzne!
Przy wstawianiu linków do konkretnych sekcji (akapitów) na wybranej stronie, np. Certyfikaty Simple CA ="Aplikowanie, rejestracja i użycie certyfikatu#Certyfikaty Simple CA", należy nazwę strony wraz z tytułem sekcji, rozdzielone znakiem #, podać w opcji Advanced w okienku link. Przy wstawianiu nazwy stron istotne jest zachowanie znaków spacji pomiędzy wyrazami oraz braków spacji pomiędzy #.
LINKI ZEWNĘTRZNE
Linki zewnętrzne np. do strony PL-Grid wstawiamy w oknie Insert Link (Ctrl+K) w opcji Web Link.
Pomoc w pisaniu stron w Confluence: https://confluence.atlassian.com/display/DOC/Using+the+Editor
Krótki opis usługi
Usługa syndykacji danych jest przeznaczona dla wszystkich badaczy i naukowców którzy są zainteresowani pozyskiwaniem dużych zbiorów danych z mediów społecznościowych. Usługa oferuje zbieranie danych z serwisu społecznościowego Twitter oraz portalu publicystycznego Salno24. Oprócz tego usługa oferuje podusługę Anotator, która pozwala na uzupełnianie zbiorów danych o dodatkowe atrybuty - ręcznie anotowane klasy. Całość usługi pozwala na uzyskanie wartościowych zbiorów danych użytecznych do badań nad sieciami społecznościowymi. Zbiory danych są przechowywane w jednolitej strukturze danych, która zapewnia kompatybilność z innymi usługami w Complex Networks.
Aktywowanie usługi
Aby korzystać z usługi należy posiadać konto w infrastrukturze PL-GRID, a następnie złożyć wniosek o dostęp do usługi na portalu https://portal.plgrid.pl/ .
Pierwsze kroki
Po aktywacji usługi na koncie PL-GRID, należy wejść na stronę portalu usługi Complex Networks https://cn.plgrid.pl/ . Następnie należy wybrać z menu (u góry strony) [Zadania] -> [Zleć syndykację].
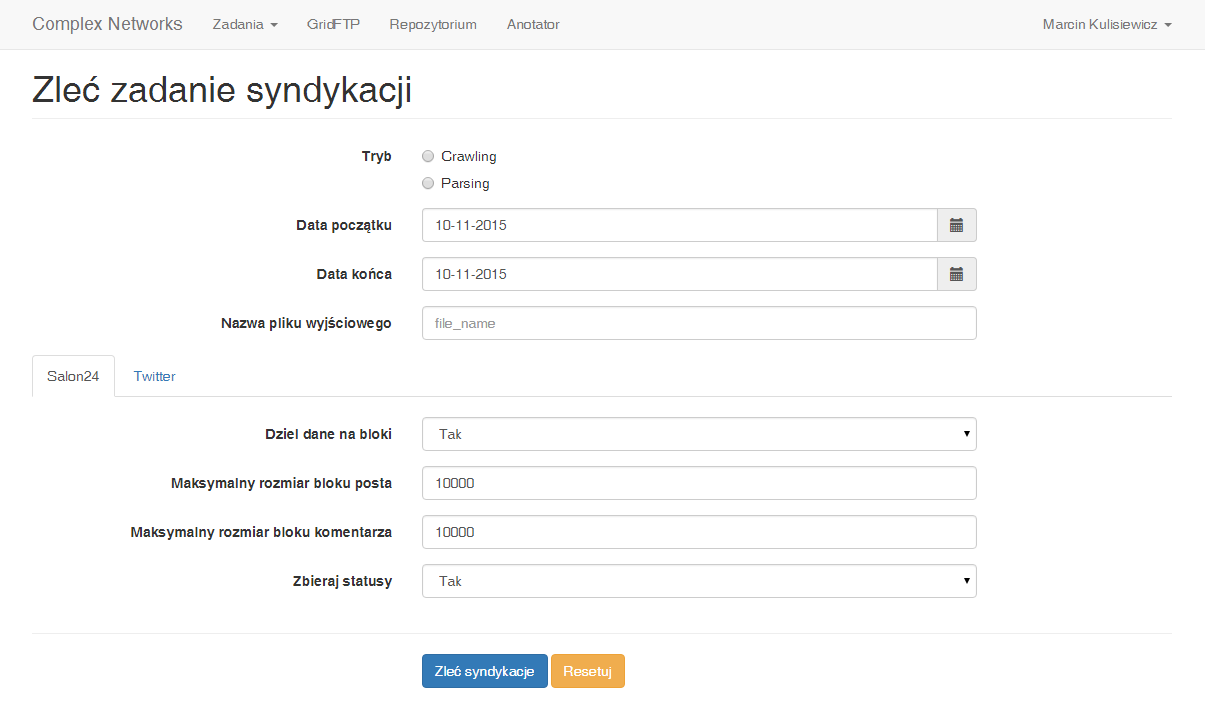
Usługa syndykacji działa w dwóch trybach: 1) Crawling oraz 2) Parsing.
Crawling
Ten tryb służy do pobierania surowych danych z wybranego źródła. Każde źródło zostanie zapisane w postaci plików html w repozytorium danych (więcej strona o DSpace).
Podstawowymi parametrami usługi jest data początkowa oraz data końcowa okresu z jakiego mają pochodzić dane. Usługa sprawdza datę publikacji i decyduje czy należy ją pobrać do zbioru użytkownika. Użytkownik ma także możliwość sparametryzować nazwę pliku wyjściowego.
Pozostałe parametry są zmienne ze względu na heterogeniczność źródeł danych. Poniżej przedstawione są parametry poszczególnych źródeł [parametr_zalecany/parametr]:
Początkowy użytkownik: nazwa użytkownika (login) którego posty mają zostać zebrane
Parsing
Ten tryb służy do przetworzenia plików zebranych w trybie Crawling do jednolitej dla wszystkich źródeł struktury danych. Parsowane dane również są umieszczane w repozytorium w postaci pliku tekstowego w formacie JSON. Schemat struktury danych dostępny tutaj.
Dodatkowe parametry:
Salon24
Dziel dane na bloki - [Tak/Nie] parametr określający czy parsowane dane mają być dzielone na bloki. Źródło danych jest bardzo duże przy parsowaniu dużej jego części może dojść do sytuacji gdy zabranie pamięci operacyjnej aby zapisać dane do repozytorium.
Maksymalny rozmiar bliku posta - maksymalna ilość postów w jednym bloku. Parametr ma zastosowanie jeśli i tylko jeśli parametr Dziel dane na bloki ma wartość TAK.
Maksymalny rozmiar bliku komentarza - maksymalna ilość komentarzy w jednym bloku. Parametr ma zastosowanie jeśli i tylko jeśli parametr Dziel dane na bloki ma wartość TAK.
Zbieraj statusy - [TAK/NIE] parametr określa czy parsowane posty mają mieć zbierane również dane o statusie społecznym (statusy w mediach społecznościowych Facebook, Twitter, Google+). Wymaga to jednak dodatkowego łączenia się z tymi serwisami co znacznie spowalnia pracę usługi.
Podgląd uruchomionych zadań
Po uruchomieniu zadania, możemy sprawdzić jego status przechodząc do listy zadań w zakładce menu górnego [Zadania] -> [Moje zadania]
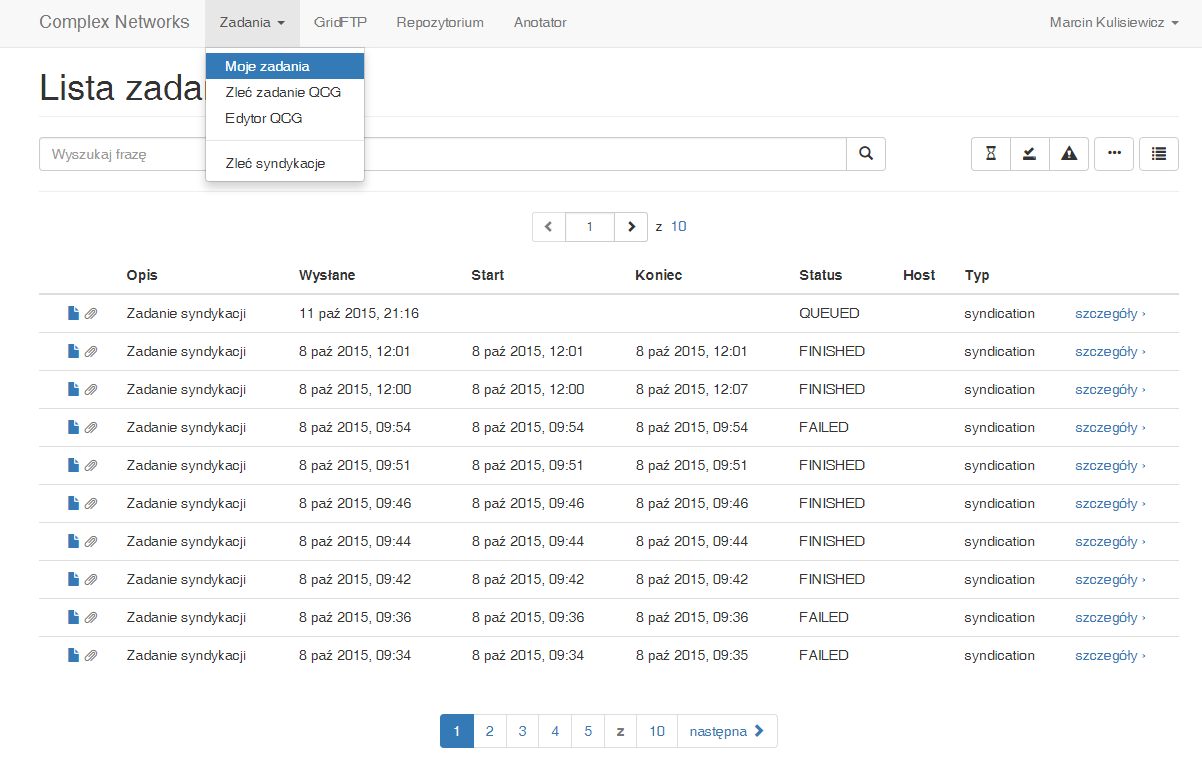
Bezpośrednio po uruchomieniu zadanie będzie posiadało status QUEUED.
Statusy zadań:
QUEUED - zadanie czeka w kolejce do uruchomienia
RUNNING - zadanie jest w trakcie wykonywania
FAILED - zadanie zakończyło się błędem w trakcie wykonywania
FINISHED - zadanie zakończyło się poprawnie
Jeżeli zadanie ma status FINISHED możliwe jest pobranie wyników zadania. Aby pobrać wyniki należy przejść do Repozytorium do Community Complex Networks, kolekcja Syndykacja. Więcej informacji w podręczniku Repozytorium.
Zaawansowane użycie
Aby skorzystać z opcji Anotatora patrz podręcznik Anotatora.
Można też dodać sekcję "Co dalej?" ze wskazaniem (odnośnikiem) do dalszej części dokumentacji, o ile jest wymagana.
Overview
Content Tools