Page History
Krótki opis usługi
Usługa jest przeznaczona dla użytkowników PLGrid, którzy chcą korzystać umożliwia korzystanie z najpopularniejszych narzędzi przetwarzania danych typu BigData . Na klastrze Zeus możemy prowadzić obliczenia uruchamianych na zasobach Infrastruktury PLGrid. Obecnie usługa jest dostępna tylko na klastrze Zeus, gdzie można prowadzić obliczenia wielowęzłowe z wykorzystaniem systemów Spark lub Hadoop wykorzystując wielowęzłową architekturę. W celu efektywnego używania oprogramowania Spark i Hadoop zalecamy zapoznanie się z Oficjalny Spark Programming Guide.
Aktywowanie usługi
Aby uzyskać dostęp do usługi należy w pierwszej kolejności posiadać dostęp do UI klastra ZeusUsługa dostepna jest dla użytkowników Infrastruktury PLGrid. W celu aktywowania należy włączyć "Dostęp do klastra ZEUS". Następnie, zawnioskować o usługę "Spark" w sekcji "Moje konto" -> "Obsluga danych typu BigData" w Portalu PLGrid.
Ograniczenia w korzystaniu
...
Pierwsze kroki
Uruchomienie zadania Spark wykorzystującego 4 rdzenie na 1 węźle w trybie klastra Spark (Spark Standalone cluster in client deploy mode)
...
$ stop-multinode-spark-cluster.sh
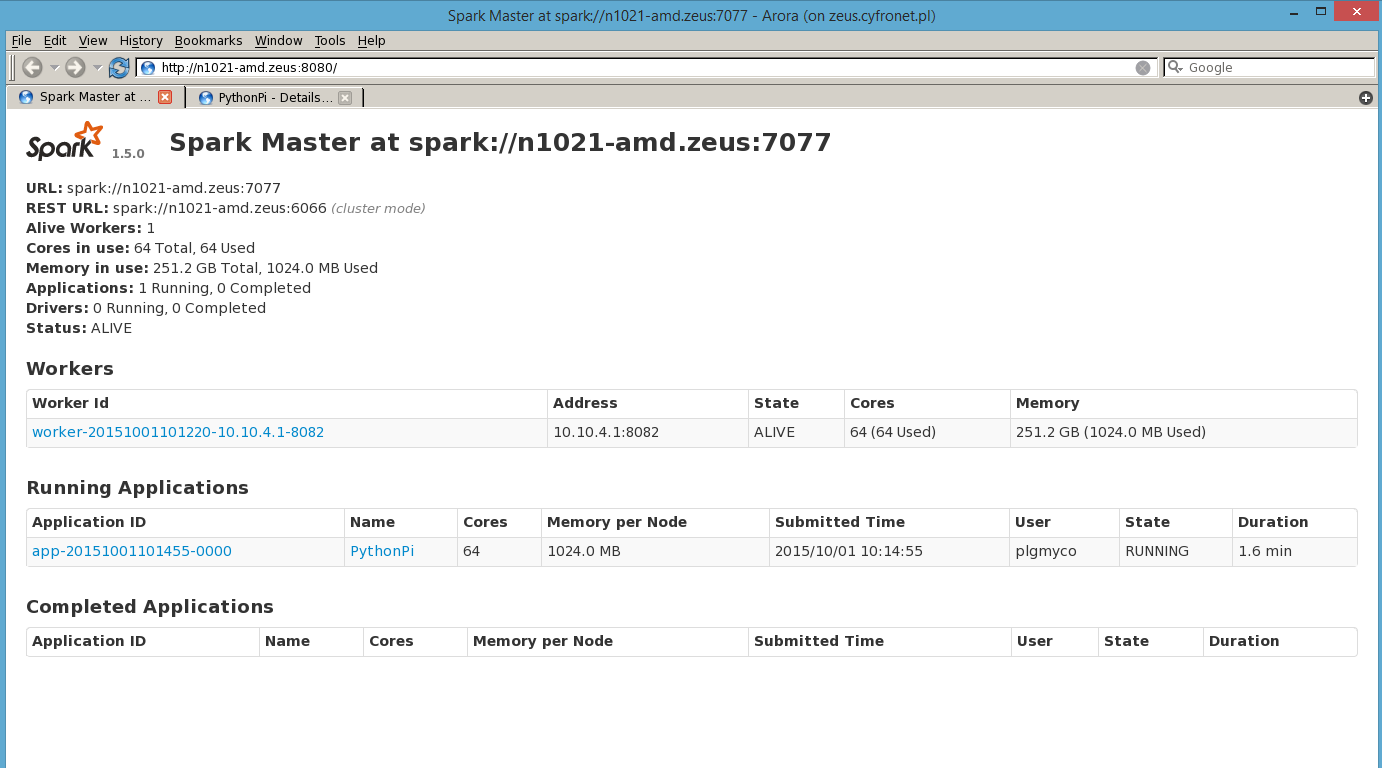
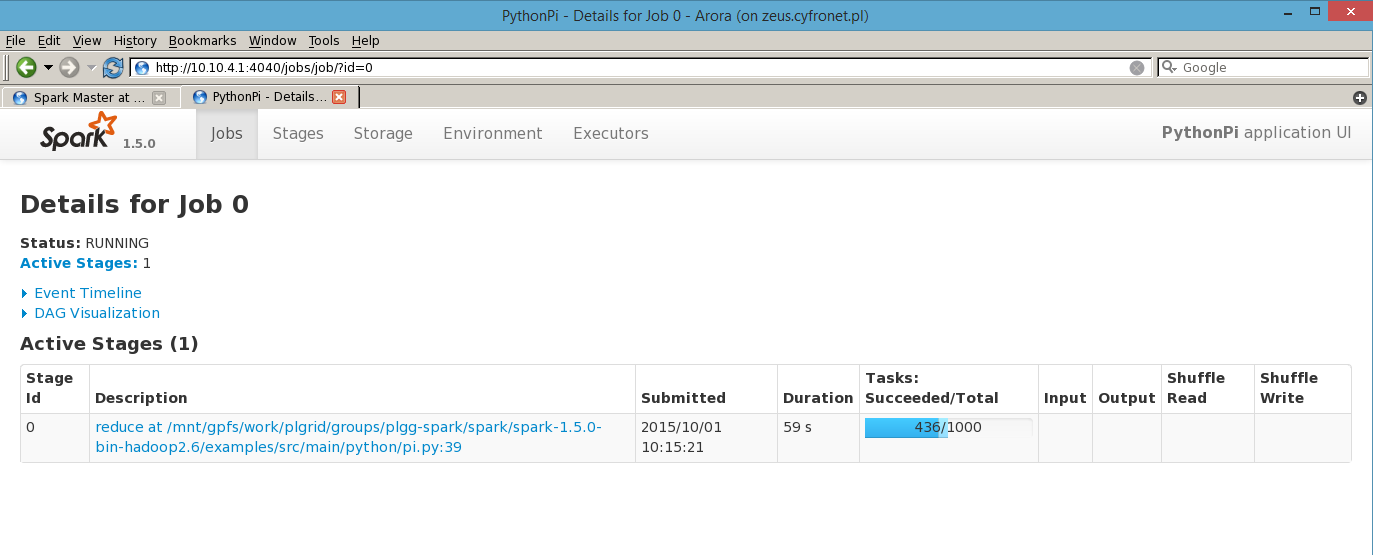
Podgląd uruchomionego klastra Spark oraz przetwarzanych na nim zadań dostępny jest przez przeglądarkę (na Zeus to aktualnie arora) na porcie 8080 węzła master.
Zaawansowane użycie
Przykłady działań na RDD w języku Python
Przykład 1:
rdd = sc.parallelize([1, 2, 3, 4])rdd.map(lambda x: 2 * x).cache().map(lambda x: 2 * x).collect()>>> [4, 8, 12, 16]Opis:
parallelize() - tworzy obiekt RDD ze zbioru
map() - transformacja RDD, operuje funkcją lambda na wszystkich elementach RDD.
cache() - zachowuje w pamięci wybrany obiekt RDD. Metodę cache() wykorzystuje się, gdy chcemy użyć wybranego RDD więcej niż raz np. w algorytmach iteratywnych jak PageRank. Jeśli w takim wypadku nie zrobimy cache() to RDD będzie wyliczone za każdym razem od nowa. Możemy również użyć podobnej metody persist().
collect() - akcja RDD zwracająca pythonową listę elementów RDD
Przykład 2:
from operator import addrdd.map(lambda x: 2 * x).reduce(add)>>> 20rdd.flatMap(lambda x: [x, x]).reduce(add)>>> 20Opis:
reduce() - akcja na RDD agregująca elementy obiektu RDD za pomocą funkcji lambda która ma przyjmować dwa argumenty i zwracać jeden wynik. reduce() zwróci ostatecznie jedną wartość. Działanie reduce() dobrze demeonstruje przykład wyszukiwania największej liczby w całej kolekcji: reduce(lambda a, b: a if (a > b) else b)
flatMap() dokonuje Transformacji na RDD. Stosuje funkcję lambda do wszystkich elementów RDD i zwraca ‘płaski’ wynik typu lista RDDs (bez zagnieżdżonych struktur), czyli elementów wyjściowych może być więcej niż wejściowych, co odróżnia działanie od map().
Uwagi
- Instalacja w ACK CYFRONET nie udostępnia systemu plików HDFS, z tego powodu korzystanie z komend 'hdfs' oraz 'hadoop fs/dfs' jest niemożliwe.
- Na wybranym węźle może być uruchomiony tylko jeden Master program w tym samym czasie. W przypadku próby uruchomienia kolejnego klastra BigData na tym samym węźle, zostanie wyświetlony komunikat, aby spróbować na innym węźle.
Zaawansowane użycie
Dokumentacja Hadoop oraz Spark w Cyfronet
Gdzie szukać dalszych informacji?
Oficjalny Spark Programming GuideDokumentacja Hadoop oraz Spark w Cyfronet
Overview
Content Tools