Page History
...
Aby móc skorzystać z infrastruktury QosCosGrid należy:
- skorzystać z wybranej metody dostępowej:
Aplikowanie o usługę
Aby móc skorzystać z zasobów projektu PL-Grid z wykorzystaniem usług dostępowych QosCosGrid konieczne jest wystąpienie o dostęp do infrastruktury QosCosGrid poprzez wykonanie prostej sekwencji kroków opisanych poniżej.
Kolejność kroków
| Info |
|---|
Punkt pierwszy nie dotyczy zarejestrowanych użytkowników PL-Gridu. Punkt drugi nie dotyczy natomiast osób, które posiadają już odpowiedni certyfikat |
- Rejestracja w Portalu PL-Grid.
- Wystąpienie o certyfikat użytkownika PL-Grid.
- Rejestracja certyfikatu w Portalu PL-Grid.
- Aplikowanie o dostęp do infrastruktury QosCosGrid.
- Po zaakceptowaniu Państwa zgłoszenia przez administratora usługi w ośrodku obliczeniowym wchodzącym w skład infrastruktury PL-Grid można zacząć korzystać z zasobów danego ośrodka wybierając dowolną metodę dostępową (klient tekstowy, graficzne narzędzia dla wybranych aplikacji).
1. Rejestracja
Aby zostać użytkownikiem PL-Gridu należy zarejestrować się w Portalu PL-Grid. Opis procedury można znaleźć „Podręczniku użytkownika”, w rozdziale: Zakładanie konta w portalu PL-Grid
2. Wystąpienie o certyfikat
Do korzystania z zasobów projektu PL-Gridu wymagane jest posiadanie certyfikatu osobistego, który poświadcza tożsamość użytkownika.
Certyfikat taki mogą wystawić użytkownikom PL-Gridu dwa centra certyfikacji (ang. Certification Authority, CA):
- Simple CA (http://plgrid-sca.wcss.wroc.pl),
- Polish Grid CA (http://www.man.poznan.pl/plgrid-ca).
Certyfikaty wystawiane przez Simple CA są łatwiejsze do uzyskania, jednak respektowane tylko w ramach infrastruktury PL-Grid. Tożsamość osoby będącej użytkownikiem PL-Gridu nie musi już być dodatkowo weryfikowana.
Certyfikaty podpisywane przez Polish Grid CA są trudniejsze do uzyskania, jednak mogą być respektowane także w infrastrukturze europejskiej, poza PL-Gridem. Tożsamość użytkownika PL-Grid musi być dodatkowo zweryfikowana przez jeden z Urzędów Rejestracji Polish Grid CA (ang. Registration Authority, RA).
Dokładny opis procedury znaleźć można w rozdziale: Aplikowanie o certyfikat.
3. Rejestracja certyfikatu w PL-Gridzie
Po uzyskaniu certyfikatu, kolejnym krokiem jest jego rejestracja w Portalu PL-Grid. Opis czynności można znaleźć w sekcji podręcznika: Rejestracja certyfikatu w przeglądarce.
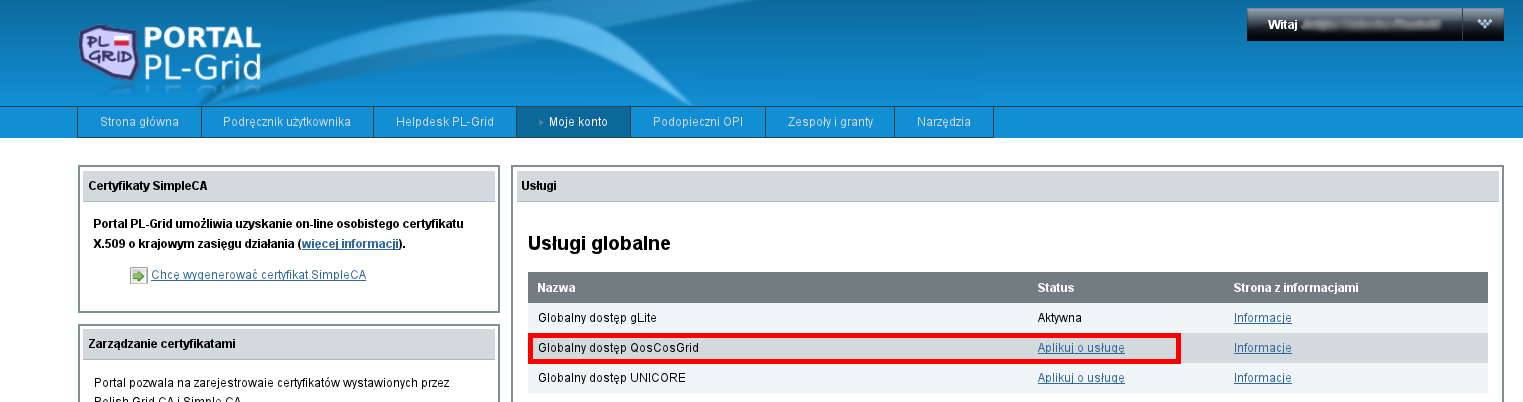
4. Aplikowanie o Globalny dostęp do infrastruktury QosCosGrid
Aby uzyskać dostęp do infrastruktury QosCosGrid należy aplikować o odpowiednią usługę za pośrednictwem Portalu. W sekcji Usługi globalne zakładki Moje konto znajduje się lista usług. Wybrać należy odnośnik Aplikuj o usługę widoczny przy pozycji Globalny dostęp QosCosGrid.
Klient tekstowy
Dostęp do infrastruktury QCG możliwy jest z dowolnego komputera, na którym zainstalowany jest klient usługi QCG-Broker (będącej częścią infrastruktury QCG), służący do zlecania i kontrolowania zadań na poziomie całego gridu. Dla wygody użytkowników uruchomiona została maszyna dostępowa do infrastruktury QCG z zainstalowaną wersją klienta dla użytkowników PL-Grid.
Klient tekstowy do infrastruktury PL-Grid dostępny jest w dwóch wersjach:
- SimpleClient - zestaw prostych poleceń wzorowanych na poleceniach systemu kolejkowego,
- AdvancedClient - ogólny klient oferujący dostęp do całej funkcjonalności infrastruktury QCG.
Maszyna dostępowa QCG
Dla wygody użytkowników klient usługi QCG-Broker zainstalowany został na ogólnodostępnej (dla użytkowników infrastruktury QCG) maszynie.
Adres maszyny: qcg.man.poznan.pl
Typ dostępu: ssh
Użytkownik i hasło są takie same jak w portalu PL-Grid.
Jednocześnie, maszyna dostępowa QCG udostępnia przestrzeń dyskową poprzez protokół gridFTP. Przestrzeń ta może być wykorzystana zarówno do przechowywania plików wejściowych, jak i wyników eksperymentów.
Logowanie: ssh <plguser>@qcg.man.poznan.pl
np.
| Code Block |
|---|
ssh plgpiontek@qcg.man.poznan.pl |
| Info |
|---|
Po zalogowaniu przed pierwszym użyciem klienta konieczna jest konfiguracja środowiska użytkownika zgodnie z wytycznymi opisanymi na maszynie dostępowej. |
| Info |
|---|
Przed użyciem klienta QCG konieczne jest ustawienie środowiska wykonawczego wykonując polecenie: module load qcg |
| Code Block |
|---|
module load qcg |
Formaty opisu zadań
Każdy eksperyment obliczeniowy, zlecany do wykonania na infrastrukturze QosCosGrid, musi być opisany przez dokument w formacie XML, zwany później „opisem zadania”. Infrastruktura QCG akceptuje opisy zadań wyrażone w:
- języku
QCG-JobProfilezdefiniowanym formalnie przez schemat XML - QCG-JobProfile. - języku
JSDL(Job Submission Description Language) z rozszerzeniemHPC Basic Profile. - języku
QCG-Simple- prosty opis w postaci pliku tekstowego, w którym każda linia może zawierać dyrektywę interpretowaną przez system QCG. Uproszczony opis przeznaczony jest do zlecania najczęściej wykonywanych zadań, nie oferuje jednak dostępu do całej funkcjonalności systemy (brak wsparcia dla kaskad zadań (ang. workflow) i zadań parametrycznych (ang. parameter sweep)).
Zmienne opisu zadania
W opisie zadania możliwe jest użycie następujących zmiennych:
- HOSTNAME - nazwa hosta (klastra) na jakim uruchomione zostało zadanie,
- HOME - katalog domowy użytkownika,
- TASK_DIR - katalog roboczy zadania,
- JOB_ID - identyfikator eksperymentu,
- TASK_ID - identyfikator zadania,
- USER_DN - DN (Distinguished Name) użytkownika (identyfikator użytkownika widoczny w certyfikacie, w formacie PEM, np. /C=PL/O=GRID/O=PSNC/CN=Tomasz Piontek)
- PROCESS_GROUP - identyfikator grupy procesów.
QCG-Simple
Zlecany plik jest plikiem tekstowym, który może zawierać dyrektywy infrastruktury QCG.
Dyrektywą jest każda linia zaczynająca się od ”#QCG”.
| Info |
|---|
Jeżeli w pliku nie zdefiniowano dyrektywy ” |
Lista dyrektyw
- queue - wybór kolejki
- note - opis zadania
- name - nazwa zadania
- output - standardowe wyjście
- error - standardowe wyjście błędów
- input - standardowe wejście
- host - wybór klastra
- stage-in-file - plik wejściowy
- stage-in-dir - katalog wejściowy
- stage-out-file - plik wynikowy
- stage-out-dir - katalog wynikowy
- grant - grant
- argument - argument aplikacji
- environment - zmienna środowiskowa
- executable - plik wykonywalny
- application - aplikacja
- persistent - usuwanie katalogu roboczego
- procs - liczba procesów
- nodes - topologia aplikacji
- walltime - czas wykonania
- memory - pamięć
- properties - parametry węzłów
- preprocess - prolog zadania
- postprocess - epilog zadania
- monitor - skrypt monitorujący zadanie
queue
queue - wybrana kolejka systemu kolejkowego.
Code Block #QCG queue=plgrid
note
note - krótka informacja o zadaniu.
Code Block #QCG note=moje pierwsze zadanie QCG
name
name - dyrektywa określająca nazwę zadania. Nazwa zadania pojawi się jako końcówka identyfikatora zadania.
Code Block #QCG name=nobel-experiment
output
output - lokalizacja gdzie ma być przegrane standardowe wyjście zadnia (stdout). Jeśli nie jest to lokalizacja gsiftp zakłada się, że jest ustalana względem katalogu, z którego zlecono zadanie.
Code Block #QCG output=gsiftp://qcg.man.poznan.pl//home/plgrid/plgpiontek/reef/outputs/${JOB_ID}.output #QCG output=output.txt
error
error - lokalizacja gdzie ma być przegrany standardowe wyjście błędów zadnia (stderr). Jeśli nie jest to lokalizacja gsiftp zakłada się, że jest ustalana względem katalogu, z którego zlecono zadanie.
Code Block #QCG error=gsiftp://qcg.man.poznan.pl//home/plgrid/plgpiontek/reef/errors/${JOB_ID}.error #QCG error=error.txt
input
input - lokalizacja skąd ma być wzięte standardowe wejście dla aplikacji (stdin). Jeśli nie jest to lokalizacja gsiftp zakłada się, że jest ustalana względem katalogu, z którego zlecono zadanie.
Code Block #QCG input=gsiftp://qcg.man.poznan.pl//home/plgrid/plgpiontek/reef/inputs/experiment.input #QCG input=input.txt
host
host - nazwa maszyny na której może być uruchomione zadanie. Może być wiele takich dyrektyw dla alternatywnych maszyn.
Code Block #QCG host=reef.man.poznan.pl #QCG host=zeus.cyfronet.pl
stage-in-file
- stage-in-file - dyrektywa kopiowania pliku wejściowego. Składnia „lokalizacja_źródłowa → nazwa_docelowa_pliku”. Lokalizacja źródłowa może być lokalizacją gsiftp lub ścieżką do pliku. W tym drugim przypadku zakłada się, że jest ustalana względem katalogu, z którego zlecono zadanie.
W przypadku braku drugiego parametru plik kopiowany jest pod nazwę źródlową.
| Code Block |
|---|
#QCG stage-in-file=gsiftp://qcg.man.poznan.pl//home/plgrid/plgpiontek/reef/inputs/input.txt -> input.txt #QCG stage-in-file=gsiftp://qcg.man.poznan.pl//home/plgrid/plgpiontek/reef/inputs/input.txt #QCG stage-in-file=input_file.txt -> input.txt #QCG stage-in-file=input_file.txt |
stage-in-dir
stage-in-dir - dyrektywa kopiowania katalogu wejściowego. Funkcjonalność i składnia analogiczna jak dla dyrektywy „stage-in-file” tyle, że kopiowany jest katalog.
Code Block #QCG stage-in-dir=gsiftp://qcg.man.poznan.pl//home/plgrid/plgpiontek/reef/inputs -> inputs #QCG stage-in-dir=gsiftp://qcg.man.poznan.pl//home/plgrid/plgpiontek/reef/inputs #QCG stage-in-dir=input_dir -> inputs #QCG stage-in-dir=input_dir
Info Skopiowanie całego katalogu w którym uruchomiony został klient odbywa się poprzez podanie ”.” (kropki) jako nazwy katalogu źródłowego i ewentualnie docelowego
Code Block #QCG stage-in-dir=. -> . #QCG stage-in-dir=. #QCG stage-in-dir=. -> input
stage-out-file
stage-out-file - dyrektywa kopiowania pliku wyjściowego. Składnia „nazwa_pliku_źródłowego → lokalizacja docelowa pliku”. Lokalizacja docelowa może być lokalizacją gsiftp lub ścieżką do pliku. W tym drugim przypadku zakłada się, że jest ustalana względem katalogu, z którego zlecono zadanie. W przypadku braku drugiego parametry plik przegrywany jest pod nazwę źródłową.
Code Block #QCG stage-out-file=results.txt -> gsiftp://qcg.man.poznan.pl//home/plgrid/plgpiontek/reef/results/result.1 #QCG stage-out-file=results.txt #QCG stage-out-file=result.txt -> ${JOB_ID}.result #QCG stage-out-file=result.txt
stage-out-dir
stage-out-dir - dyrektywa kopiowania katalogu wyjściowego. Funkcjonalność i składnia analogiczna jak dla dyrektywy „stage-out-file” tyle, że kopiowany jest katalog.
Code Block #QCG stage-out-dir=results -> gsiftp://qcg.man.poznan.pl//home/plgrid/plgpiontek/reef/results/${JOB_ID} #QCG stage-out-dir=results -> gsiftp://qcg.man.poznan.pl//home/plgrid/plgpiontek/reef/results/${JOB_ID} #QCG stage-out-dir=results -> result #QCG stage-out-dir=resultsInfo Skopiowanie całego katalogu w którym wykonane było zadanie odbywa się poprzez podanie ”.” (kropki) jako nazwy katalogu źródłowego.
Code Block #QCG stage-out-dir=. -> . #QCG stage-out-dir=. #QCG stage-out-dir=. -> output
grant
grant - nazwa grantu, w ramach którego ma być wykonane zadanie.
Code Block #QCG grant=plgpiontek_grant
argument
argument - argument aplikacji w przypadku użycia dyrektywy „executable” lub „application”. Argument może wystąpić wielokrotnie. Każdy argument powinien być przekazany w osobnej dyrektywie. Argumenty do aplikacji przekazywane są w kolejności ich wystąpienia w pliku opisu
Code Block #QCG argument=arg1 #QCG argument=arg2
environment
environment - ustawianie zmiennych środowiskowych. Składnia „nazwa → wartość”. Każda zmienna musli być ustawiana w osobnej linii.
Code Block #QCG environment=name -> piontek #QCG environment=location -> poznan
executable
executable - lokalizacja pliku do uruchomienia. Lokalizacja może być lokalizacją gsiftp lub ścieżką do pliku. W tym drugim przypadku przyjmuje się, że jest ustalana względem katalogu, z którego zlecone zostało zadanie. Opcjonalnie możliwe jest podanie nazwy pod jaką ma być zapisany plik wykonywalny. W przypadku braku nazwy zapisywany jest pod oryginalna nazwą.
Code Block #QCG executable=gsiftp://qcg.man.poznan.pl//home/plgrid/plgpiontek/reef/executables/exec1 #QCG executable=executables/exec1 #QCG executable=executables/exec1 -> exec-file
application
application - nazwa aplikacji do uruchomienia.
Code Block #QCG application=namd
persistent
persistent - dyrektywa określająca czy po zakończeniu zadania system ma pozostawić katalog roboczy, w którym wykonywane było zadanie.
Code Block #QCG persistent
procs
procs - liczba rdzeni obliczeniowych, na których ma być wykonane zadanie. (Stosowane dla zadań MPI.)
Code Block #QCG procs=32
nodes
nodes - dyrektywa pozwalająca zdefiniować na ilu węzłach i rdzeniach w ramach węzła ma być uruchomione zadanie. Opcjonalnie można podać ile procesów ma być uruchomione na węzłach. Domyślnie, jeżeli nie zostanie podane inaczej, liczna procesów równa jest liczbie rdzeni przydzielonych w ramach węzła. Składnia liczna_węzłów:liczba_rdzeni_na_węźleliczba_procesów.
Code Block #QCG nodes=10:5:1 #QCG nodes=12:12
walltime
- walltime - dyrektywa definiująca deklarowany przez użytkownika czas wykonania zadania w formacie PnYnMnDTnHnMnS, w formacie ISO 8601 gdzie:
- P - obowiązkowy znak rozpoczynający definicję okresu,
- nY - liczba lat,
- nM - liczba miesięcy,
- nD - liczba dni,
- T - separator czasu (musi być obecny, jeśli zdefiniowane są poniższe wartości)
- nH - liczba godzin,
- nM - liczba minut,
- nS - liczba sekund.
Code Block #QCG walltime=P3DT12H
memory
memory - dyrektywa definiująca deklarowane maksymalne zapotrzebowanie aplikacji na pamięć operacyjną. Podana wartość jest w MB.
Code Block #QCG memory=1024
properties
properties - dyrektywa definiująca właściwości węzłów na których ma być uruchomione zadanie.
Code Block #QCG properties=mpi,ib,lustre
preprocess
preprocess - dyrektywa umożliwiająca wykonanie polecenia/skryptu przed uruchomieniem właściwego zadania. Wartością dyrektywy może być polecenie lub ścieżka do pliku, który ma być wykonany.
Code Block #QCG preprocess=mkdir outputs
Code Block #QCG preprocess=preprocess-script.sh
postprocess
postprocess - dyrektywa umożliwiająca wykonanie polecenia/skryptu po zakończeniu się właściwego zadania. Wartością dyrektywy może być polecenie lub ścieżka do pliku, który ma być wykonany.
Code Block #QCG postprocess=tar cvf wynik.tar *
Code Block #QCG preprocess=postprocess-script.sh
monitor
monitor - dyrektywa umożliwiająca zdefiniowanie skryptu, który zostanie uruchomiony przed uruchomieniem właściwego zadania i zabity po zakończeniu zadania. Funkcjonalność ta umożliwia w prosty sposób zaimplementowanie monitoringu aplikacji. Uruchomiony skrypt może cyklicznie wyszukiwać w wyniku aplikacji zadanych wzorców i przesyłać je w dowony sposób do użytkownika.
Code Block #QCG monitor=monitor-script.sh
Przykładowe opisy
Uruchomienie na klastrze galera aplikacji „gaussian”.
Code Block #QCG queue=plgrid-long #QCG name=etanal #QCG note=etanal Gaussian #QCG output=${JOB_ID}.output #QCG error=${JOB_ID}.error #QCG stage-in-file=etanal.gjf -> etanal.gjf #QCG stage-out-file=wynik.tar -> ${JOB_ID}.tar #QCG nodes=1:12 #QCG host=galera.task.gda.pl #QCG persistent #QCG walltime=P7D #QCG notify=mailto:piontek@man.poznan.pl #QCG memory=15360 #QCG preprocess=echo START #QCG application=g09 #QCG argument=etanal.gjf #QCG postprocess=tar cvf wynik.tar *- Eksperyment polegający na:
- przegraniu z katalogu, z którego wykonano polecenie qcg-sub podkatalogu inputs na klaster na docelowy klaster (reef).
- zleceniu do wykonania na klastrze reef w kolejce plgrid polecenia /bin/tar pakującego przegrany wczesnej katalog inputs do pliku output.tgz.
przesłaniu pliku output.tgz do katalogu, z którego wykonano polecenie qcg-sub pod tę samą nazwę.
Code Block #!/bin/bash #QCG queue=plgrid #QCG persistent #QCG host=reef.man.poznan.pl #QCG output=output #QCG error=error #QCG stage-in-dir=inputs -> inputs /bin/tar -czf output.tgz inputs/input.* #QCG stage-out-file=output.tgz -> output.tgz
QCG-JobProfile
QCG-JobProfile jest XMLowym językiem opisu zadań QCG umożliwiającym dostęp do całej funkcjonalności oferowanej przez usługi QCG.
Język opisu zadań QCG składa się z następujących elementów:
- qcgJob- element grupujący zadania w logiczny eksperyment
- description - opis eksperymentu obliczeniowego
- task- definicja pojedynczego zadania
- description - opis zadania
- candidateHosts - lista potencjalnych zasobów obliczeniowych, na których zadanie ma być wykonane
- requirements- definicja wymagań zasobowych dla zadania
- resourceRequirements - opis wymagań zasobowych
- topology - topologia grup procesów
- execution - deklaracja typu zadania
- executable - deklaracja aplikacji lub pliku wykonywalnego
- arguments - argumenty zadnia
- stdin - standardowe wejście
- stdout - standardowe wyjście
- stderr - standardowe wyjście błędów
- stageInOut - deklaracja danych wejściowych/wyjściowych
- environment - zmienne środowiskowe
- reservation - rezerwacje
- executionTime - wymagania czasowe
- workflow - zależności kolejnościowe zadań
- parameterSweep - definicja zmienności parametrów
qcgJob - definicja eksperymentu
Opis każdego eksperymentu obliczeniowego QCG rozpoczyna się elementem qcgJob W elemencie tym można podać następujące atrybuty:
- appId - definiowany przez użytkownika element, który pojawi się jako część identyfikatora eksperymentu. Dozwolone są znaki dopuszczalne w nazwach katalogów w systemie Linux (obowiązkowy, typ: tekst),
- project - identyfikator grantu, w ramach którego zlecany jest eksperyment (opcjonalny, typ: tekst),
commitWait- atrybut określający czy przetwarzanie eksperymentu ma być wstrzymane do czasu aż użytkownik wywoła polecenie commit_job (opcjonalny, dopuszczalne wartości: true,false, wartość domyślna: false),
Code Block <qcgJob appId="moj_eksperyment" project="grant123" commitWait="true"> ... </qcgJob>
Każdy eksperyment obliczeniowy składa się z minimum jednego zadania - elementu task o unikalnym identyfikatorze.
Code Block <qcgJob appId="moj_eksperyment" project="grant123" commitWait="true"> <task taskId="zadanie_1"> ... </task> <task taskId="zadanie_2"> ... </task> </qcgJob>
description - opis eksperymentu
Eksperyment może zawierać opisujący go opcjonalny element description.
| Code Block |
|---|
<qcgJob appId="moj_eksperyment"> <description>Najważniejszy eksperyment w PL-Grid<description> </qcgJob> |
task - definicja zadania
Element task odpowiada pojedynczemu zadaniu obliczeniowemu wchodzącemu w skład eksperymentu (qcgJob).
Task może/musi zawierać następujące atrybuty:
- taskId - unikalny identyfikator zadania w ramach eksperymentu. Dozwolone są znaki dopuszczalne w nazwach katalogów w systemie Linux (obowiązkowy, typ: tekst)
- persistent - określa czy po zakończeniu zadania system ma automatycznie usunąć czy pozostawić katalog, w którym wykonywało się zadanie (opcjonalny, dopuszczalne wartości: true,false, wartość domyślna: false),
- crucial - określa czy poprawne zakończenie zadania jest istotne dla pomyślnego zakończenia całego eksperymentu (opcjonalny, dopuszczalne wartości: true,false, wartość domyślna: true),
- commitWait - atrybut określający czy przetwarzanie zadania ma być wstrzymane do czasu aż użytkownik wywoła polecenie commit_task (opcjonalny, dopuszczalne wartości: true,false, wartość domyślna: false),
| Code Block |
|---|
<qcgJob appId="moj_eksperyment"> ... <task taskId="zadanie_2" persistent="true" commitWait="false"> ... </task> |
description - opis zadania
Zadanie może zawierać opisujący go opcjonalny element description.
| Code Block |
|---|
<task taskId="zadanie_2" persistent="true" commitWait="false"> <description>Zadanie wyznaczające ...</description> </task> |
candidateHosts - lista potencjalnych zasobów obliczeniowych
Zlecając eksperyment do wykonania można dla każdego zadnia zdefiniować listę potencjalnych maszyn, spośród których QCG-Broker będzie dokonywał wyboru. W przypadku braku elementu candidateHosts Broker wybiera spośród wszystkich dostępnych maszyn, na których użytkownik ma prawo wykonywać zadania.
| Code Block |
|---|
<candidateHosts>
<hostName>reef.man.poznan.pl</hostName>
<hostName>zeus.cyfronet.pl</hostName>
</candidateHosts>
|
requirements - definicja wymagań zasobowych dla zadania
Element ten pozwala na wyrażenie wymagań zasobowych dotyczących zleconego zadania. Możliwe jest zdefiniowanie prostych wymagań opisujące tylko parametry węzłów obliczeniowych (element resourceRequirements) lub, w przypadku zadań rozproszonych, topologii i wymagań dla poszczególnych grup procesów (element topology).
resourceRequirements - opis wymagań zasobowych
Element zawierający opis wymagań zasobowych dotyczący parametrów maszyny obliczeniowej. Element ten może zawierać jeden lub więcej elementów computingResource ze zdefiniowaną listą parametrów - elementy hostParameter. Element hostParameter ma atrybut computingParameterName określający po nazwie definiowany parametr. Wartość parametru może być liczbowa, przekazywana w elemencie value, lub tekstowa w elemencie stringValue.
Lista możliwych parametrów:
- osname - nazwa systemu operacyjnego,
- ostype - typ systemu operacyjnego,
- cpuarch - architektura procesora
- cpucount - liczba procesorów
- gpucount - liczba akceleratorów graficznych
- application - dostępne aplikacje
- queue - nazwa kolejki, do której ma być zlecone zadanie
| Code Block |
|---|
<requirements>
<resourceRequirements>
<computingResource>
<hostParameter name="gcpucount">
<value>3</value>
</hostParameter>
</computingResource>
</resourceRequirements>
</requirements>
|
| Code Block |
|---|
<requirements>
<resourceRequirements>
<computingResource>
<hostParameter name="queue">
<stringValue value="plgrid-long"/>
</hostParameter>
</computingResource>
</resourceRequirements>
</requirements>
|
| Code Block |
|---|
<requirements>
<resourceRequirements>
<computingResource>
<hostParameter name="application">
<stringValue value="abinit"/>
</hostParameter>
</computingResource>
</resourceRequirements>
</requirements>
|
topology - topologia grup procesów
Element topology służy do opisu zadań rozproszonych składających się z potencjalnie wielu grup procesów o odmiennych wymaganiach zasobowych.
W przypadku zadań z wieloma grupami procesów, lub przy podziale grupy pomiędzy wiele zasobów, QCG-Broker dokonuje koalokacji zasobów dla wszystkich grup.
Element topology zawiera nie mniej niż jeden element processes definiujący pojedynczą grupę procesów.
Element processes ma następujące atrybuty:
- processesId - identyfikator grupy procesów (opcjonalny, typ: tekst),
- masterGroup - atrybut ten pozwala określić, do której grupy należeć ma proces master rozproszonej aplikacji (opcjonalny, typ: logiczny, domyślnie false). W przypadku, gdy żadna grupa nie jest wybrana proces master wybierany jest niedeterministycznie,
- divisible - atrybut określający czy dana grupa może być dzielona pomiędzy wiele zasobów (opcjonalny, typ: logiczny, domyślna wartość: true),
Każdy element processes może zawierać następujące elementy: - processesCount - liczność grupy procesów,
- processesMap - mapa alokacji procesów dla zadań hybrydowych (określa liczbę węzłów obliczeniowych dla zadania oraz procesów na każdym z węzłów),
- candidateHosts - lista potencjalnych maszyn, na których może być wykonana grupa procesów,
- reservation - rezerwacja, w ramach której ma być uruchomiona grupa procesów. Element ten wymaga jednoznacznego wyboru maszyny poprzez candidateHosts,
resourceRequirements - opis wymagań zasobowych dla grupy procesów,
Code Block <topology> <processes processesId="SMC:collector:distributor:Blob:voxelizer:thrombusMapper" masterGroup="true"> <processesCount> <value>1</value> </processesCount> <candidateHosts> <hostName>reef.man.poznan.pl</hostName> </candidateHosts> </processes> <processes processesId="BF"> <processesCount> <value>32</value> </processesCount> <candidateHosts> <hostName>huygens.sara.nl</hostName> </candidateHosts> <reservation type="LOCAL">p6012.huygens.sara.nl.537.r</reservation> </processes> <processes processesId="DD"> <processesCount> <value>4</value> </processesCount> <candidateHosts> <hostName>zeus.cyfronet.pl</hostName> </candidateHosts> </processes> </topology>W poniższym przykładzie zadanie uruchomione zostanie na 3 węzłach (liczba elementów processesPerNode), na każdym węźle do zadania przydzielone zostanie 8 slotów obliczeniowych (atrybut slotsPerNode). Na węzłach uruchomione zostaną odpowiednio 1, 8, 8 procesów (wartości elementu processesPerNode).
Code Block <topology> <processes processesId="process"> <processesMap slotsPerNode="8"> <processesPerNode>1</processesPerNode> <processesPerNode>8</processesPerNode> <processesPerNode>8</processesPerNode> </processesMap> <candidateHosts> <hostName>grass1.man.poznan.pl</hostName> </candidateHosts> </processes> </topology>
execution - deklaracja typu zadania
Element execution opisuje uruchomienie pojedynczego zadania. Zawiera informację jaki jest jego typ, plik wykonywalny, argumenty, strumienie wejścia, wyjścia i błędów, pliki i katalogi z danymi wejściowymi i wynikami oraz zmienne środowiskowe. Atrybut type określa rodzaj zadania oraz sposób w jaki będzie wykonywane. Wspierane są następujące typy:
- single - aplikacja będąca pojedynczym procesem,
- open_mpi, mpi_mp - zadanie rozproszone MPI. Zadanie może składać się z wielu alokacji, a stan zadania zależy od stanu wszystkich alokacji. Jeżeli element stdout/etderr wskazuje na katalog, to standardowe wyjścia zgrywane są ze wszystkich alokacji. Jeżeli element stdout/etderr wskazuje na plik, to standardowe wyjścia zgrywane jest tylko z procesu mastera. Pliki wyjściowe kopiowane są tylko z głównej alokacji (proces master). W przypadku, gdy jedna z alokacji zakończy się niepowodzeniem, wykonywanie pozostałych jest automatycznie anulowane. Ustawiane są następujące zmienne środowiskowe:
- OMPI_SESSION_ID - unikalny identyfikator sesji,
- OMPI_PROCESSES_ID - identyfikator grupy procesów,
- OMPI_MASTER_GROUP - informacja czy dana alokacja zawiera proces master,
- OMPI_PROCESSES - łaczna liczba procesów,
- OMPI_COLORS - opis kolorów dla zadania (procesy o tym samym kolorze znajdują się na tym samym zasobie),
- QCG_MACHINEFILE - lokalizacja pliku machinefile,
- mapper - zadanie rozproszone. Różni się od typu open_mpi tym, że pliki wyjściowe przegrywane są ze wszystkich alokacji. Dla tego typu zadnia przekazywane są następujące zmienne środowiskowe: OMPI_PROCESSES_ID, OMPI_MASTER_GROUP, OMPI_PROCESSES,
- proactive - zadanie rozproszone środowiska PROACTIVE. Różni się od zadania open_mpi tym, że do głównej alokacji kopiowany jest tworzony automatycznie plik proactive description. Do zadania przekazywane są następujące zmienne środowiskowe:
- PROACITIVE_SESSION_ID - identyfikator sesji, mający postać '{JOBID}:{TASKID}'
- PROACTIVE_PROCESSES_ID - identyfikator grupy procesów
- PROACTIVE_MASTER_GROUP - informacja czy dana alokacja zawiera proces master,
- PROACTIVE_PROCESSES - łączna liczba procesów.
| Code Block |
|---|
<execution type="single"> ... </execution> |
executable - deklaracja aplikacji lub pliku wykonywalnego
Element określający aplikację oraz jej wersję (element application) lub plik wykonywalny (element execFile) dla danego zadania.
| Code Block |
|---|
<executable>
<application name="abinit" version="6.10.1"/>
</executable>
|
| Code Block |
|---|
<executable>
<execFile>
<file>
<location type="URL">file:////usr/bin/cal</location>
</file>
</execFile>
</executable>
|
| Code Block |
|---|
<executable>
<execFile>
<file>
<location type="URL">gsiftp://qcg.man.poznan.pl/~/executable</location>
</file>
</execFile>
</executable>
|
arguments - argumenty zadnia
Lista argumentów dla uruchomienia aplikacji. Każdy argument powinien być podany jako osobna wartość.
| Code Block |
|---|
<arguments> <value>argument_1</value> <value>argument_2</value> <value>argument_3</value> </arguments> |
stdin - standardowe wejście
Element stdin umożliwia przypisanie pliku do standardowego wejścia procesu. Element stdin musi zawierać lokalizację pojedynczego pliku. Wspierane są następujące typy lokalizacji:
- URL - fizyczna lokalizacja pliku w formacie URL (podstawowym wspieranym protokołem jest gridFTP),
REFERENCE - logiczna referencja do innego pliku w eksperymencie typu workflow.
Code Block <stdin> <file> <location type="URL">gsiftp://qcg.man.poznan.pl/~/experiments/stdin.txt</location> </file> </stdin>Code Block <stdin> <file> <location type="REFERENCE">ref1</location> </file> </stdin>
stdout - standardowe wyjście
Element stdout pozwala zdefiniować, gdzie powinno zostać przegrane standardowe wyjście aplikacji. Plik ten przegrywany jest jednokrotnie po zakończeniu wykonywania aplikacji. Element stdout może zawierać lokalizację pojedynczego pliku (element file), lub w przypadku aplikacji rozproszonej wykonującej się na wielu zasobach lokalizację katalogu (element directory), do którego przegrane zostaną pliki ze standardowym wyjściem z każdej alokacji.
Wspierane są następujące typy lokalizacji:
- URL - fizyczna lokalizacja pliku w formacie URL (podstawowym wspieranym protokołem jest gridFTP),
REFERENCE - logiczna referencja do innego pliku w eksperymencie typu workflow.
Code Block <stdout> <file> <location type="URL">gsiftp://qcg.man.poznan.pl/~/experiments/stdout.txt</location> </file> </stdout>Code Block <stdout> <directory> <location type="URL">gsiftp://qcg.man.poznan.pl/~/experiments/stdouts</location> </directory> </stdout>Code Block <stdout> <file> <location type="REFERENCE">ref1</location> </file> </stdout>
stderr - standardowe wyjście błędów
Element stderr pozwala zdefiniować, gdzie powinno zostać przegrane standardowe wyjście błędów aplikacji. Plik ten przegrywany jest jednokrotnie po zakończeniu wykonywania aplikacji. Element stderr może zawierać lokalizację pojedynczego pliku (element file), lub w przypadku aplikacji rozproszonej wykonującej się na wielu zasobach lokalizację katalogu (element directory), do którego przegrane zostaną pliki ze standardowym wyjściem błędu z każdej alokacji.
Wspierane są następujące typy lokalizacji:
- URL - fizyczna lokalizacja pliku w formacie URL (podstawowym wspieranym protokołem jest gridFTP),
REFERENCE - logiczna referencja do innego pliku w eksperymencie typu workflow.
Code Block <stderr> <file> <location type="URL">gsiftp://qcg.man.poznan.pl/~/experiments/stdout.txt</location> </file> </stderr>Code Block <stderr> <directory> <location type="URL">gsiftp://qcg.man.poznan.pl/~/experiments/stdouts</location> </directory> </stderr>Code Block <stderr> <file> <location type="REFERENCE">ref1</location> </file> </stderr>
stageInOut - deklaracja danych wejściowych/wyjściowych
Element stdInOut umożliwia zarządzanie danymi (plikami i katalogami) wejściowymi i wyjściowymi aplikacji. Element ten musi zawierać co najmniej jeden element opisujący plik (element file) lub katalog (element directory). Elementy file i directory muszą zawierać lokalizacje odpowiednio pojedynczego pliku lub katalogu i mają następujący zbiór atrybutów:
- name - nazwa pliku lub katalogu (obowiązkowy, typ: tekst)
- type - typ pliku lub katalogu (obowiązkowy, możliwe wartości „in” dla plików/katalogów wejściowych, „out” - dla plików/katalogów wyjściowych),
- required - element określający czy przegranie pliku/katalogu jest niezbędne do pomyślnego zakończenia zadania (opcjonalny, typ logiczny, domyślna wartość true),
- permissions - atrybut umożliwiający zdefiniowanie praw do pliku/katalogu (opcjonalny, typ tekstowy, format: cztery cyfry z zakresu 0-7 - format systemu Unix/Linux),
- creationFlag - atrybut określający zachowanie systemu w przypadku istnienia pliku/katalogu docelowego (opcjonalny, typ wyliczeniowy). Dopuszczalne wartości:
- APPEND - plik zostanie „dopisany” na koniec istniejącego,
- OVERWRITE - istniejący plik zostanie nadpisany,
- DONTOVERWRITE - plik docelowy nie jest nadpisywany, zgłaszany jest błąd.
Elementy file i directory muszą zawierać element location zawierający typ i lokalizację pliku/katalogu. Wspierane są 2 typy loklizacji:
- URL - lokalizacja fizycznego pliku/katalogu w formacie URL (podstawowym wspieranym protokołem jest gridFTP).
- REFERENCE - logiczna referencja do pliku/katalogu w eksperymecie typu worflow.
W lokalizacji plików i katalogów wyjściowych dozwolone jest stosowanie zmiennych: - JOB_ID - identyfikator eksperymentu
TASK_ID - identyfikator zadania.
Code Block <stageInOut> <file name="date.out" type="out" creationFlag="APPEND" permissions="644"> <location type="URL">gsiftp://fury.man.poznan.pl/~/examples/dates</location> </file> </stageInOut>Code Block <stageInOut> <file name="input" type="in"> <location type="URL">gsiftp://qcg.man.poznan.pl/~/plgrid/staging/input.txt</location> </file> <file name="output.tar" type="out"> <location type="URL">gsiftp://qcg.man.poznan.pl/~/plgrid/output/output-${JOB_ID}.tar</location> </file> <directory name="results" type="out"> <location type="URL">gsiftp://qcg.man.poznan.pl/~/plgrid/output/output-${JOB_ID}-${TASK_ID}.tar</location> </directory> </stageInOut>Code Block <stageInOut> <file name="ps" type="in"> <location type="REFERENCE">ref1</location> </file> <file name="ps.tgz" type="out"> <location type="URL">gsiftp://qcg.reef.man.poznan.pl/ps.tgz</location> </file> </stageInOut>
environment - zmienne środowiskowe
Lista zmiennych środowiskowych i ich wartości, które przekazane zostaną przy uruchomieniu zadania
| Code Block |
|---|
<environment> <variable name="PATH">/home/piontek</variable> <variable name="VERBOSE">true</variable> </environment> |
reservation - rezerwacje
Element reservation pozwala zdefiniować rezerwację, do której ma być zlecone zadanie.
Element posiada atrybuty:
- type - typ rezerwacji
- QCG - identyfikator rezerwacji założonej przez QCG-Broker,
- LOCAL - identyfikator rezerwacji założonej bezpośrednio w systemie kolejkowym.
- processGroupId - identyfikator grupy procesów, dla której rezerwacja została założona. Istotne w przypadku, gdy rezerwacja założona została dla zadania z grupami procesów.
executionTime - wymagania czasowe
Element executionTime pozwala zdefiniować wymagania czasowe dla zadania. Element ten musi zawierać element executionDuration definiujący długość czasu obliczeń oraz opcjonalnie element timePeriod określający okno czasowe, w którym zadanie ma być wykonane. Element timePeriod musi zawierać element periodStart określający początek okna czasowego oraz periodEnd (koniec okna) lub periodDuration (długość okna czasowego).
| Code Block |
|---|
<executionTime> <executionDuration>P0Y0M0DT0H30M</executionDuration> </executionTime> |
| Code Block |
|---|
<executionTime>
<executionDuration>P0Y0M0DT24H0M</executionDuration>
<timePeriod>
<periodStart>2011-11-23T14:29:00</periodStart>
<periodEnd>2011-11-24T18:29:00</periodEnd>
</timePeriod>
</executionTime>
|
workflow - definicja zależności kolejnościowych zadań
Element workflow pozwala definiować złożone zależności kolejnościowe pomiędzy zadaniami w eksperymencie. Dla każdego zadania możliwe jest zdefiniowanie od jakich innych zadań ono zależy, używając zagnieżdżonych warunków z wykorzystaniem operatorów AND/OR oraz dowolnych stanów zadań. Zależności pomiędzy zadaniami nie mogą zawierać cykli. Element workflow może zawierać jeden z następujących elementów:
- parent - element zawierający identyfikator zadania, od którego zależy opisywane zadanie. Element ten ma opcjonalny atrybut „triggerState” ze stanem zadania. Domyślnie system przyjmuje, że stanem tym jest stan FINISHED.
- and - logiczny operator AND pozwalający tworzyć złożone warunki. Element and może zawierać elementy parent, and i or.
or - logiczny operator OR pozwalający tworzyć złożone warunki. Element or może zawierać elementy parent, and i or.
Code Block <workflow> <parent>task_1</parent> </workflow>
Code Block <workflow> <parent triggerState="FINISHED">task_2</parent> </workflow>
Code Block <workflow> <and> <parent triggerState="FINISHED">task_1</parent> <parent triggerState="RUNNING">task_2</parent> </and> </workflow>Code Block <workflow> <or> <parent triggerState="FINISHED">task_1</parent> <parent triggerState="RUNNING">task_2</parent> </or> </workflow>Code Block <workflow> <or> <parent triggerState="FINISHED">task_1</parent> <and> <parent triggerState="FINISHED">task_2</parent> <parent triggerState="FINISHED">task_3</parent> </and> </or> </workflow>
parameterSweep - definicja zmienności parametrów
Element parameterSweep służy do definiowania zadań parametrycznych, to znaczy takich, w których ta sama aplikacja uruchamiana jest wielokrotnie dla różnych parametrów. QCG-Broker umożliwia definiowanie wielowymiarowej przestrzeni parametrów, w której jednocześnie wg podanych reguł może zmienianych być wiele parametrów. Możliwe jest definiowanie różnych schematów zmienności parametrów (kolejności zmieniania wartości wielu parametrów) jak również zakresów zmienności pojedynczych elementów. Element parameterSweep musi zawierać co najmniej jeden element parameter definiujący zmienność pojedynczego parametru. Element parameter zawiera następujące elementy:
- name - nazwa parametru,
- value - element definiujące zmienność parametru. Zawiera jeden z elementów:
- loop - zmiana parametru w pętli. Element zawiera:
- start - dolne ograniczenie pętli,
- end - górne ograniczenie pętli,
- step - krok zmienności,
- except - opcjonalny element definiujący listę wartości (element value), które powinny zostać pominięte
set - zmiana parametru ze zdefinowanego zbioru wartości.
- loop - zmiana parametru w pętli. Element zawiera:
| Code Block |
|---|
<parametersSweep>
<parameter>
<name>arg1</name>
<value>
<loop>
<start>0</start>
<end>9</end>
<step>1</step>
<except>
<value>3</value>
<value>6</value>
</except>
</loop>
</value>
</parameter>
</parametersSweep>
|
| task | arg1 |
|---|---|
| task_1 | 1 |
| task_2 | 2 |
| task_3 | 3 |
| task_4 | 4 |
| task_5 | 5 |
| task_6 | 6 |
| task_7 | 7 |
| task_8 | 8 |
| task_9 | 9 |
| Code Block |
|---|
<parametersSweep>
<parameter>
<name>arg2</name>
<value>
<set>
<item>a</item>
<item>b</item>
</set>
</value>
</parameter>
</parametersSweep> |
| task | arg2 |
|---|---|
| task_1 | a |
| task_2 | b |
| Code Block |
|---|
<parametersSweep>
<parameter>
<name>arg1</name>
<value>
<loop>
<start>0</start>
<end>5</end>
<step>1</step>
<except>
<value>3</value>
<value>4</value>
</except>
</loop>
</value>
</parameter>
<parameter>
<name>arg2</name>
<value>
<set>
<item>a</item>
<item>b</item>
</set>
</value>
</parameter>
</parametersSweep> |
| task | arg1 | arg2 |
|---|---|---|
| task_1 | 0 | a |
| task_2 | 1 | b |
| task_3 | 2 | a |
| task_4 | 5 | b |
| Code Block |
|---|
<parametersSweep>
<parameter>
<name>arg1</name>
<value>
<loop>
<start>0</start>
<end>5</end>
<step>1</step>
<except>
<value>3</value>
<value>4</value>
</except>
</loop>
</value>
<parameter>
<name>arg2</name>
<value>
<set>
<item>a</item>
<item>b</item>
</set>
</value>
</parameter>
</parameter>
</parametersSweep> |
| task | arg1 | arg2 |
|---|---|---|
| task_1 | 0 | a |
| task_2 | 0 | b |
| task_3 | 1 | a |
| task_4 | 1 | b |
| task_5 | 2 | a |
| task_6 | 2 | b |
| task_7 | 5 | a |
| task_8 | 5 | b |
Przykładowe opisy eksperymentów
EKSPERYMENT: Pobranie pliku report, spakowanie go aplikacją tar i przegranie wyniku do podanej lokalizacji. Zadanie wykonane zostanie na klastrze reef.man.poznan.pl. Standardowe strumienie wyjścia przegrane zostaną do podanych lokalizacji.
| Code Block |
|---|
<grmsJob appId="eksperyment">
<task taskId="tar">
<candidateHosts>
<hostName>reef.man.poznan.pl</hostName>
</candidateHosts>
<execution type="single">
<executable>
<execFile>
<file>
<location type="URL">file:////bin/tar</location>
</file>
</execFile>
</executable>
<arguments>
<value>cfv</value>
<value>report.tar</value>
<value>report</value>
</arguments>
<stdout>
<file>
<location type="URL">gsiftp://qcg.man.poznan.pl/~stdout-${JOB_ID}</location>
</file>
</stdout>
<stderr>
<file>
<location type="URL">gsiftp://qcg.man.poznan.pl/~/stderr-${JOB_ID}</location>
</file>
</stderr>
<stageInOut>
<file name="report" type="in">
<location type="URL">gsiftp://fury.man.poznan.pl/~/examples/report</location>
</file>
<file name="report.tar" type="out">
<location type="URL">gsiftp://fury.man.poznan.pl/~/examples/report.tar</location>
</file>
</stageInOut>
</execution>
</task>
</grmsJob> |
Eksperyment: Wykonanie zbioru zadań „calc” dla miesięcy roku 2012 z pominięciem miesięcy 3 i 6. Standardowe lokalizacje przegrane zostaną do podanej lokalizacji.
| Code Block |
|---|
<grmsJob appId="kalendarze">
<task taskId="calendar">
<execution type="single">
<executable>
<execFile>
<file>
<location type="URL">file:////usr/bin/cal</location>
</file>
</execFile>
</executable>
<arguments>
<value>${PS_month}</value>
<value>2012</value>
</arguments>
<stdout>
<file>
<location type="URL">${TASK_DIR}/stdout.txt</location>
</file>
</stdout>
</execution>
<parametersSweep>
<parameter>
<name>month</name>
<value>
<loop>
<start>1</start>
<end>12</end>
<step>1</step>
<except>
<value>3</value>
<value>6</value>
</except>
</loop>
</value>
</parameter>
</parametersSweep>
</task>
</grmsJob> |
Eksperyment: Prosty workflow składający się z dwóch zadań (aplikacja date). Drugie zadanie wykonane będzie po zakończeniu pierwszego. Strumienie wyjściowe przegrane zostaną do podanych lokalizacji.
| Code Block |
|---|
<qcgJob appId="example1">
<task taskId="date_1">
<execution type="single">
<executable>
<execFile>
<file>
<location type="URL">file:////bin/date</location>
</file>
</execFile>
</executable>
<stdout>
<file>
<location type="URL">gsiftp://qcg.man.poznan.pl/~/date-${JOB_ID}-${TASK_ID}.txt</location>
</file>
</stdout>
</execution>
</task>
<task taskId="date_2">
<execution type="single">
<executable>
<execFile>
<file>
<location type="URL">file:////bin/date</location>
</file>
</execFile>
</executable>
<stdout>
<file>
<location type="URL">gsiftp://qcg.man.poznan.pl/~/date-${JOB_ID}-${TASK_ID}.txt</location>
</file>
</stdout>
</execution>
<workflow>
<parent triggerState="FINISHED">date_1</parent>
</workflow>
</task>
</qcgJob> |
Eksperyment: Prosty workflow, w którym drugie zadanie „pakuje” wyjście polecenia „ps” w pierwszego zadania. Plik przekazywane są „przez” referencje.
| Code Block |
|---|
<qcgJob appId="ps_tar"> <task taskId="ps"> <execution type="single"> <executable> <execFile> <file> <location type="URL">file:////bin/ps</location> </file> </execFile> </executable> <arguments> <value>aux</value> </arguments> <stdout> <file> <location type="REFERENCE">ref1</location> </file> </stdout> </execution> </task> <task taskId="tar"> <execution type="single"> <executable> <execFile> <file> <location type="URL">file:////bin/tar</location> </file> </execFile> </executable> <arguments> <value>czf</value> <value>ps.tgz</value> <value>ps</value> </arguments> <stageInOut> <file name="ps" type="in"> <location type="REFERENCE">ref1</location> </file> <file name="ps.tgz" type="out"> <location type="URL">gsiftp://qcg.reef.man.poznan.pl/ps.tgz</location> </file> </stageInOut> </execution> <workflow> <parent triggerState="FINISHED">ps</parent> </workflow> </task> </qcgJob> |
Wersje klienta tekstowego
SimpleClient
QCG-SimpleClient oferuje prosty, wzorowany na poleceniech systemu kolejkowego, interfejs do infrastruktury QCG.
Polecenia
- qcg-sub - zlecenie zadania do wykonania na infrastrukturze QCG zgodnie z uproszczonym opisem,
- qcg-list - wyświetlenie listy zleconych zadań wraz z informacjami o nich,
- qcg-info - wyświetlenie szczegółowej informacji o danym zadaniu,
- qcg-peek - podgląd wyjścia (stdout, stderr) aplikacji,
- qcg-proxy - utworzenie certyfikatu proxy użytkownika,
- qcg-cancel - anulowanie zadania.
Składnia poleceń
- qcg-sub
plik_z_opisem- ścieżka do pliku z uproszczonym opisem zadania
| Code Block |
|---|
qcg-sub /home/piontek/tasks/date.qcg qcg-sub ./tasks/date.qcg |
- qcg-list
\[liczba jednostka\] \[stan,\[stan\]\]- lista zadań. Opcjonalnie można podać z jakiego czasu mają być zadania - z ostatnich „liczba” dni („d”), godzin („h”), minut („m”). Drugim opcjonalnym parametrem jest lista stanów zadań oddzielonych przecinkami (bez spacji). W przypadku niepodania stanów wyświetlane są zadania niezakończone.
| Code Block |
|---|
qcg-list qcg-list 7d qcg-list 1m qcg-list 7d finished qcg-list 1m finished,failed |
Dla wygody użytkowników zamiast listy stanów możliwe jest podanie zdefiniowanych stałych:
- all - zadania we wszystkich stanach,
- terminated - zadania zakończone,
- unterminated - zadania niezakończone.
| Code Block |
|---|
qcg-list 7d all qcg-list 7d terminated qcg-list 7d unterminated |
- qcg-info
jobId pokaz_opis- jobId - identyfikator eksperymentu. Jeśli pokaz_opis ma wartość „true” to dodatkowo wyświetlany jest opis zadnia. Domyślną wartością jest „false”.
| Code Block |
|---|
qcg-info J1331196390748_date_3099 true |
- gcg-peek
jobId \[liczba_znaków\]- jobId - identyfikator eksperymentu, liczba_znaków - liczba znaków do wyświetlenia,
| Code Block |
|---|
qcg-peek J1331196390748_date_3099 qcg-peek J1331196390748_date_3099 10 |
- qcg-proxy
| Code Block |
|---|
qcg-proxy |
- qcg-cancel
jobId- identyfikator eksperymentu
| Code Block |
|---|
qcg-cancel J1331196390748_date_3099 |
...
Overview
Content Tools